2023-08-29
- WebGPU
- WGSL
- Graphics
WebGPU 컴퓨트 셰이더를 이용한 인터랙티브 파티클 구현
들어가기
WebGPU는 WebGL의 후속으로, 일종의 OpenGL API 래퍼에 가까운 형태였던 WebGL에 비해, WebGPU는 운영체제에 따라 다른 새로운 종류의 모던 API(ex. Direct3D12, Metal, Vulkan)을 브라우저로 가져오고자 하는 시도라고 볼 수 있다.
WebGPU가 무엇이 좋은지에 대한 이야기는 이 곳을 찾아보도록 하고, 이번 포스트에서는 이 중 WebGPU의 컴퓨트 셰이더와 그 활용에 대해 이야기해보고자 한다.
기존의 WebGL에는 컴퓨트 셰이더가 존재하지 않았고, 때문에 보다 일반적인 목적으로 GPU를 활용해야 하는 경우(GPGPU)에도, 억지로 렌더링 목적의 API를 끼워 맞추어 사용해야 했다. (이미지 출처)

이러한 방식의 이용은 코드 자체가 이해하기에 많이 어색하다는 문제가 있었고, 계산 간 공유 메모리 액세스와 같은 기본적인 기능이 부족했기 때문에 중복 작업 및 성능 최적화에 있어 아쉬운 부분이 있었다.
컴퓨트 셰이더(Compute Shader)는 바로 그 기존의 문제점을 해결해주는 WebGPU의 새 기능이다. 컴퓨트 셰이더는 렌더링 작업의 엄격한 구조에 제약을 받지 않으면서도 GPU의 대규모 병렬 특성을 활용할 수 있게 해주어, 유연한 프로그래밍 모델을 제공해준다.

따라서, 기존 WebGL에서 JS에서 처리하던 알고리즘을 컴퓨트 셰이더로 GPU에 포팅할 때, 상당히 큰 성능 향상을 기대할 수 있게 되었다. 이번 포스트에서 다루고자 하는 것이 바로 이 컴퓨트 셰이더를 사용하는 방법과, 그로 인한 성능 향상을 눈으로 확인하는 것이다.
아주 간단한 컴퓨트 셰이더 만들기
시작하기에 앞서, "아주 간단한"이라는 말은 틀렸을지도 모른다. 하는 작업은 아주 간단하지만, 그것을 구축하기 위해 많은 작업을 필요로 하는, 간단한 컴퓨트 셰이더를 하나 만들어 볼 것이다.
여기서 만들 컴퓨트 파이프라인의 다이어그램을 그려보자면 아래와 같은 형태가 된다. (출처 - WebGPUFundamentals)

가장 먼저, 이용자의 디바이스 및 브라우저 환경이 WebGPU를 지원하는지를 확인해야 한다. 크롬과 몇몇 브라우저가 공식적으로 지원하기 시작했지만, 여전히 WebGPU는 실험적인 기능이기 때문에, 이용 불가능한 상황이 드물지 않게 발생할 수 있다.
caniuse에 따르면 WebGPU는 현 시점에서 단 25.97%의 지원율을 보인다. 특히나 모바일의 경우는 현재는 아예 지원하지 않는다.
const main = async () => {
try {
if (!navigator.gpu) {
throw new Error('WebGPU not supported on this browser.');
}
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) {
throw new Error('No appropriate GPUAdapter found.');
}
const device = await adapter.requestDevice();
if (!device) {
throw new Error('need a browser that supports WebGPU');
}
// ...
}
main();
이제 컴퓨트 셰이더 모듈과 컴퓨트 파이프라인(pipeline)을 만들고, 만든 셰이더 모듈을 파이프라인에 연결한다.
셰이더 내에 작성한 WGSL 코드는 각 실행마다 버퍼의 각 데이터에 2를 곱해주는 것이 전부다.
const module = device.createShaderModule({
label: 'My Shader',
code: `
@group(0) @binding(0) var<storage, read_write> data: array<f32>;
@compute @workgroup_size(1) fn computeMain(
@builtin(global_invocation_id) id: vec3<u32>
) {
let i = id.x;
data[i] = data[i] * 2.0;
}
`,
});
const pipeline = device.createComputePipeline({
label: 'My Pipeline',
layout: 'auto',
compute: {
module,
entryPoint: 'computeMain',
},
});
이제 실질적인 데이터 인풋을 넘겨주어야 하는데, 이는 버퍼(buffer)를 통해 이루어진다. 버퍼를 새로 생성하고, 버퍼의 용도에 맞게 적절히 usage를 입력해준 다음, 인풋이 될 데이터를 버퍼에 작성한다. WebGPU에서는 데이터를 주고받는 모든 경우에 TypedArray를 사용한다는 점도 유의할만한 부분이다. (ex. Float32Array)
const workBuffer = device.createBuffer({
label: 'work buffer',
size: input.byteLength,
usage:
GPUBufferUsage.STORAGE | // 스토리지 버퍼로 사용
GPUBufferUsage.COPY_SRC | // 복사 작업의 소스로 사용
GPUBufferUsage.COPY_DST, // 읽기/쓰기의 대상으로 사용
mappedAtCreation: false,
});
const input = new Float32Array([1, 3, 5]);
device.queue.writeBuffer(workBuffer, 0, input);
이제 이 버퍼를 셰이더 측에서 읽을 수 있도록 바인드 그룹(bind group)을 만들어 설정 해주어야 한다. 바인드 그룹 및 버퍼 바인딩은 앞서 작성했던 셰이더 코드의 내용과 일치해야 한다. 앞서 본 것처럼 이 경우는 바인드 그룹과 버퍼 모두 둘다 0번 바인딩을 사용하고 있으니 똑같이 입력해주면 된다.
const bindGroup = device.createBindGroup({
label: 'bindGroup for work buffer',
layout: pipeline.getBindGroupLayout(0),
entries: [{ binding: 0, resource: { buffer: workBuffer } }],
});
이제 파이프라인과 바인드 그룹을 통해 실질적인 작업 명령을 인코딩한다.
const encoder = device.createCommandEncoder({
label: 'doubling encoder',
});
const pass = encoder.beginComputePass({
label: 'doubling compute pass',
});
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
pass.dispatchWorkgroups(input.length);
pass.end();
이렇게 작업을 수행하고 나서의 결과는 JS 측에서 곧바로 확인할 방법이 없다. 다시 말해, 그 결과를 받아올 결과 버퍼를 따로 마련해서, 워크 버퍼에 작성된 내용을 결과 버퍼로 복사해주어야 한다.
const resultBuffer = device.createBuffer({
label: 'result buffer',
size: input.byteLength,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
mappedAtCreation: false,
});
encoder.copyBufferToBuffer(
workBuffer,
0,
resultBuffer,
0,
resultBuffer.size,
);
이제 명령 인코딩을 마치고, 그 결과로 나온 명령 버퍼를 GPU에 제출한다. 실제 GPU에서의 작업은 명령을 제출하게 되는 이 시점에서부터 일어난다.
const commandBuffer = encoder.finish();
device.queue.submit([commandBuffer]);
이제 완료된 작업을 JS측에서 확인할 수 있도록, 결과 버퍼를 매핑하고, 그 결과를 TypedArray로 변환해준다.
여기서 유의하는 것은, 결과 버퍼에 대한 매핑이 유지되어 있는 동안에만 getMappedRange 메서드로 그 결과를 CPU로 가져올 수 있다는 점이다. 만약 이를 매핑 해제(unmap)하고 나면, resultBuffer에 대해 다시 매핑을 해주어야 한다.
await resultBuffer.mapAsync(GPUMapMode.READ);
const result = new Float32Array(resultBuffer.getMappedRange().slice(0));
resultBuffer.unmap();
console.log('input', input);
console.log('result', result);
그러면 아래와 같은 입/출력 결과값을 확인할 수 있다.
Float32Array(3) [ 1, 3, 5 ]
Float32Array(3) [ 2, 6, 10 ]
컴퓨트 셰이더의 연산 결과를 버텍스 셰이더로 넘기기
여기부터가 다루고 싶었던 진짜다. 컴퓨트 셰이더로 연산을 처리하고, 그 결과를 그대로 버텍스 셰이더에서 사용하여 뭔가를 렌더링해보자.
먼저 컴퓨트 셰이더를 좀 수정해보겠다. POINT_COUNT개 만큼의 점을 생성할 것이기 때문에, 랜덤한 위치 정보를 생성하여 버퍼에 담는다.
@group(0) @binding(0) var<storage, read_write> position: array<vec2f>;
@compute @workgroup_size(64, 1, 1) fn computeMain(
@builtin(global_invocation_id) globalId: vec3<u32>
) {
// 우측 상단으로 조금씩 이동시킨다.
position[globalId.x].x += 0.001;
position[globalId.x].y += 0.001;
}
const POINT_SIZE = 10;
const POINT_COUNT = 20;
const pointPositions = new Float32Array(
[...new Array(POINT_COUNT)]
.map(() => {
// 클립 공간에 흩뿌리므로, -1 ~ 1 사이의 값으로 정규화한다.
const position = [Math.random() * 2 - 1, Math.random() * 2 - 1];
return position;
})
.flat(),
);
const vertexBuffer = device.createBuffer({
label: 'vertex buffer',
size: pointPositions.byteLength,
usage:
GPUBufferUsage.VERTEX |
GPUBufferUsage.STORAGE |
GPUBufferUsage.COPY_SRC |
GPUBufferUsage.COPY_DST,
mappedAtCreation: false,
});
device.queue.writeBuffer(vertexBuffer, 0, pointPositions);
이제 여러 개의 셰이더를 사용할 것이기 때문에, 변수명과 레이블도 수정해줬다.
const computeModule = device.createShaderModule({
label: 'compute shader',
code: computeShader,
});
const computePipeline = device.createComputePipeline({
label: 'compute pipeline',
layout: 'auto',
compute: {
module: computeModule,
entryPoint: 'computeMain',
},
});
const bindGroup = device.createBindGroup({
label: 'bindGroup for computing vertex buffer',
layout: computePipeline.getBindGroupLayout(0),
entries: [{ binding: 0, resource: { buffer: vertexBuffer } }],
});
이제 렌더 파이프라인의 차례다. 렌더 파이프라인과 프래그먼트 셰이더를 구축하기 위한 일련의 과정들을 거쳐야 한다.
// 인덱스 버퍼와 위치 정보에 기반하여 원하는 크기의 점을 그리는 셰이더 코드
const renderShader = `
struct VSInput {
@location(0) position: vec2f,
@builtin(vertex_index) vertexIndex: u32
}
struct VSOutput {
@builtin(position) position: vec4f,
}
struct Uniforms {
pointSize: f32,
resolution: vec2f,
};
@group(0) @binding(0) var<uniform> uniforms: Uniforms;
@vertex
fn vertexMain(in: VSInput) -> VSOutput {
let vertexPosition = getVertexPosition(in.position, in.vertexIndex);
var vsOut: VSOutput;
vsOut.position = vec4f(vertexPosition, 1., 1.);
return vsOut;
}
fn getVertexPosition(center: vec2f, vertexIndex: u32) -> vec2f {
let pointSize = vec2f(uniforms.pointSize) / uniforms.resolution;
let quadPosition = array(
vec2f(-.5, .5),
vec2f(-.5, -.5),
vec2f(.5, .5),
vec2f(.5, -.5),
);
let pos = center + quadPosition[vertexIndex] * pointSize;
return pos;
}
@fragment
fn fragmentMain(in: VSOutput) -> @location(0) vec4f {
return vec4f(vec3f(1.), 1.);
}
`
const context = canvas.getContext('webgpu')!;
const canvasFormat = navigator.gpu.getPreferredCanvasFormat();
context.configure({
device,
format: canvasFormat,
});
const renderPassDescriptor = {
colorAttachments: [
{
view: context.getCurrentTexture().createView(),
loadOp: 'clear' as const,
storeOp: 'store' as const,
},
],
};
const vertexBufferLayout: GPUVertexBufferLayout = {
arrayStride: 8,
stepMode: 'instance', // 여기서 인스턴스 모드를 사용했음에 유의
attributes: [
{
format: 'float32x2' as const,
offset: 0,
shaderLocation: 0,
},
],
};
const shaderModule = device.createShaderModule({
code: renderShader,
});
const renderPipeline = device.createRenderPipeline({
layout: 'auto',
vertex: {
module: shaderModule,
entryPoint: 'vertexMain',
buffers: [vertexBufferLayout],
},
fragment: {
module: shaderModule,
entryPoint: 'fragmentMain',
targets: [
{
format: canvasFormat,
},
],
},
});
const uniformBindGroup = device.createBindGroup({
layout: renderPipeline.getBindGroupLayout(0),
entries: [{ binding: 0, resource: { buffer: uniformBuffer } }],
});
위에서 버텍스 버퍼에 인스턴스 모드를 사용한 부분에 유의할 필요가 있다. 현재 버텍스 버퍼의 데이터는 각 점의 위치 정보 position이다. 그렇기 때문에 이 위치 정보를 통해, 유니폼의 pointSize, resolution을 통해 점을 적절하게 그려줘야 한다. (이에 대한 세부적인 내용은 WGSL 코드인 renderShader에 작성되어 있다.)
기본값인 vertex 모드에서는 세 개의 정점을 전달할 때마다 삼각형을 그리게 될 것이므로, 현재 작성된 셰이더 코드 및 구현하고자 하는 내용에 부적합하다. 따라서 instance 모드를 활용한다.
점을 그릴 때 메모리 관점에서 이득을 얻기 위해 인덱스 버퍼를 활용할 것이므로, 이 또한 구성해준다.
const indexData = new Uint32Array(
[...new Array(POINT_COUNT)]
.map((_, index) => {
const offset = index * 4;
return [0, 1, 2, 2, 1, 3].map((i) => i + offset);
})
.flat(),
);
const indexBuffer = device.createBuffer({
label: 'index buffer',
size: indexData.byteLength,
usage: GPUBufferUsage.INDEX | GPUBufferUsage.COPY_DST,
mappedAtCreation: false,
});
device.queue.writeBuffer(indexBuffer, 0, indexData);
셰이더 코드 상으로 유니폼(uniform)으로 resolution과 pointSize도 사용하게 될 것이므로, 이에 대한 버퍼도 생성해준다.
const UNIFORM_BUFFER_SIZE =
2 * 4 + // pointSize ~ 패딩에 유의!
2 * 4; // resolution
// 16 byteLength
const uniformValues = new Float32Array(UNIFORM_BUFFER_SIZE / 4);
const uniformBuffer = device.createBuffer({
label: 'uniform buffer',
size: UNIFORM_BUFFER_SIZE,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST,
mappedAtCreation: false,
});
const uniformBindGroup = device.createBindGroup({
layout: renderPipeline.getBindGroupLayout(0),
entries: [{ binding: 0, resource: { buffer: uniformBuffer } }],
});
이제 requestAnimationFrame으로 매 애니메이션 프레임마다 GPU에 컴퓨트 파이프라인을 통한 연산 명령을 전달하고, 렌더 파이프라인으로 그 결과에 대한 그리기를 요청한다.
resizeCanvasToDisplaySize는 매 프레임마다 현재 브라우저의 innerWidth, innerHeight를 감지하여 캔버스의 크기를 리사이징해주는 함수다.
코드를 간결하게 하기 위해, 명령 인코더와 컴퓨트/렌더 패스에 따로 레이블(label)을 추가하지 않았지만, 실제로는 추가하는 것을 디버깅 관점에서 아주 권장한다.
const render = (time: number) => {
resizeCanvasToDisplaySize(canvas);
// Compute
const computeEncoder = device.createCommandEncoder();
const computePass = computeEncoder.beginComputePass();
computePass.setPipeline(computePipeline);
computePass.setBindGroup(0, bindGroup);
// POINT_COUNT개 이상의 연산을 처리할 수 있도록 워크 그룹을 디스패치해야 하기 때문에, 올림 처리한다.
// `64`로 나누는 것은, 셰이더 코드 상에서 확인할 수 있듯, 워크 그룹의 사이즈가 64이기 때문이다.
computePass.dispatchWorkgroups(Math.ceil(POINT_COUNT / 64));
computePass.end();
const commandBuffer = computeEncoder.finish();
device.queue.submit([commandBuffer]);
// Render
renderPassDescriptor.colorAttachments[0].view = context
.getCurrentTexture()
.createView();
const renderEncoder = device.createCommandEncoder();
const renderPass = renderEncoder.beginRenderPass(renderPassDescriptor);
renderPass.setPipeline(renderPipeline);
uniformValues.set([POINT_SIZE], 0); // pointSize
uniformValues.set([canvas.width, canvas.height], 2); // resolution
device.queue.writeBuffer(uniformBuffer, 0, uniformValues);
renderPass.setBindGroup(0, uniformBindGroup);
renderPass.setVertexBuffer(0, vertexBuffer);
// 인덱스 버퍼를 사용해서 그린다는 점에 유의
renderPass.setIndexBuffer(indexBuffer, 'uint32');
renderPass.drawIndexed(6, pointPositions.length / 2);
renderPass.end();
device.queue.submit([renderEncoder.finish()]);
requestAnimationFrame(render);
};
requestAnimationFrame(render);
여기까지 했다면, 우측 상단으로 조금씩 이동하는 몇 개의 점들을 확인할 수 있다!
컴퓨트 셰이더를 통해, 각 점의 위치를 +0.001씩 이동시키고, 이를 그대로 버텍스 셰이더로 넘겨 그리기를 처리하고 있으므로, 의도한 대로 잘 처리되고 있다.

아주 많은 개수의 파티클 만들고 동작 구체화하기
앞선 과정을 거쳐 컴퓨트 셰이더로 연산을 처리하고, 그 결과를 그대로 렌더 패스로 넘겨 원하는 그리기 작업을 수행했다. 이제 훨씬 더 많은 양의 파티클을 만들고, 좀 더 그럴싸한 움직임을 갖추도록 해보자.
먼저 particleBuffer라는 이름의 새 버퍼를 만들고, 여기에 각 파티클의 회전 방향과 속도를 담을 것이다.
// 점의 크기를 DPR에 기반하여 조절한다.
const POINT_SIZE = 2 * window.devicePixelRatio;
const POINT_COUNT = 100_000; // 10만 개의 파티클을 만든다.
const particleData = new Float32Array(
[...new Array(POINT_COUNT)]
.map(() => {
const angle = Math.random() * Math.PI * 2; // 0 ~ 2PI
const speed = Math.random() * 0.01; // 0 ~ 0.01
return [angle, speed];
})
.flat(),
);
const particleBuffer = device.createBuffer({
label: 'Particle buffer',
size: particleData.byteLength,
usage:
GPUBufferUsage.STORAGE |
GPUBufferUsage.COPY_SRC |
GPUBufferUsage.COPY_DST,
mappedAtCreation: false,
});
device.queue.writeBuffer(particleBuffer, 0, particleData);
const bindGroup = device.createBindGroup({
label: 'bindGroup for computing vertex buffer',
layout: ComputePipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: { buffer: vertexBuffer } },
{ binding: 1, resource: { buffer: particleBuffer } }, // 바인드 그룹에 추가
],
});
컴퓨트 셰이더 코드도 변경한다. 각 점의 위치에서, particleBuffer에 담긴 회전 방향과 속도를 읽어와, 이를 기반으로 해당 회전 방향과 속도를 적용하여 새로운 위치를 계산해 조금씩 이동 시킨다.
struct Particle {
angle: f32,
speed: f32
}
@group(0) @binding(0) var<storage, read_write> positions: array<vec2f>;
@group(0) @binding(1) var<storage, read_write> particle: array<Particle>;
@compute @workgroup_size(64, 1, 1) fn computeMain(
@builtin(local_invocation_id) localId : vec3<u32>,
@builtin(global_invocation_id) globalId: vec3<u32>
) {
let angle = particle[globalId.x].angle;
let speed = particle[globalId.x].speed;
positions[globalId.x].x += rotate(angle, positions[globalId.x]).x * speed;
positions[globalId.x].y += rotate(angle, positions[globalId.x]).y * speed;
}
fn rotate(angle: f32, position: vec2f) -> vec2f {
let x = position.x * cos(angle) - position.y * sin(angle);
let y = position.x * sin(angle) + position.y * cos(angle);
return vec2f(x, y);
}
최초에 흩뿌려진 수많은 점들이, 중심축인 가운데를 기준으로 회전하다가 결국 가운데로 수렴하는 형태가 된다.

인터랙션 추가하기
이제 여기에, 마우스 위치를 중심으로 파티클이 원 모양을 그리며 흩뿌려지는 효과를 추가하고, 애니메이션을 수정해보자.
컴퓨트 셰이더에서 현재 마우스의 위치와, 이에 대한 클립 공간 좌표를 얻기 위해 캔버스 해상도 resolution와 마우스 위치 mousePosition, 그리고 각 프레임 간의 시간 간격을 나타내는 deltaTime을 추가하여 넘겨줄 유니폼 버퍼를 새로 만들어준다.
const COMPUTE_UNIFORM_BUFFER_SIZE =
4 * 2 + // deltaTime
4 * 2 + // mousePosition
4 * 2; // resolution
const computeUniformValues = new Float32Array(
COMPUTE_UNIFORM_BUFFER_SIZE / 4,
);
const computeUniformBuffer = device.createBuffer({
label: 'compute uniform buffer',
size: COMPUTE_UNIFORM_BUFFER_SIZE,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST,
mappedAtCreation: false,
});
const bindGroup = device.createBindGroup({
label: 'bindGroup for computing vertex buffer',
layout: ComputePipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: { buffer: vertexBuffer } },
{ binding: 1, resource: { buffer: particleBuffer } },
{ binding: 2, resource: { buffer: computeUniformBuffer } }, // 유니폼 버퍼 추가
],
});
마우스 위치를 감지하기 위해, 이벤트 리스너를 추가하고, 마우스 위치 정보를 담아준다.
type MousePosition = {
x: number;
y: number;
};
let mousePosition: MousePosition | null = null;
window.addEventListener('pointermove', (e) => {
const dpr = window.devicePixelRatio;
const clientX = e.clientX * dpr;
const clientY = e.clientY * dpr;
if (!mousePosition) {
mousePosition = { x: clientX, y: clientY };
} else {
mousePosition.x = clientX;
mousePosition.y = clientY;
}
});
이후 유니폼 값들을 실제로 넘겨주도록 한다.
// ...
let time = 0;
const render = (newTime: number) => {
// ...
const deltaTime = newTime - time;
time = newTime;
computeUniformValues.set([deltaTime], 0); // deltaTime
computeUniformValues.set(
[
mousePosition?.x || canvas.width / 2,
canvas.height - (mousePosition?.y || canvas.height / 2),
],
2,
); // mousePosition
computeUniformValues.set([canvas.width, canvas.height], 4); // resolution
device.queue.writeBuffer(computeUniformBuffer, 0, computeUniformValues);
// ...
}
그리고 해당 값들을 이용해, 셰이더 코드를 수정한다.
굳이 매 프레임마다 일정한 값만큼 이동시키지 않고 deltaTime을 이용하는 이유는, 저마다 다른 재생률을 가진 모니터에서 애니메이션이 동일한 속도로 구현되게끔 하기 위해서다.
struct Particle {
angle: f32,
speed: f32
}
struct Uniforms {
deltaTime: f32,
mousePosition : vec2f,
resolution: vec2f,
}
@group(0) @binding(0) var<storage, read_write> positions: array<vec2f>;
@group(0) @binding(1) var<storage, read_write> particle: array<Particle>;
@group(0) @binding(2) var<uniform> uniforms: Uniforms;
@compute @workgroup_size(64, 1, 1) fn computeMain(
@builtin(global_invocation_id) globalId: vec3<u32>
) {
let deltaTime = uniforms.deltaTime * .5;
let resolution = uniforms.resolution;
let mousePosition = (uniforms.mousePosition * 2. - resolution) / resolution;
let angle = particle[globalId.x].angle;
let speed = particle[globalId.x].speed;
// 마우스 위치에 따라 각 파티클의 위치를 deltaTime에 기반하여 조금씩 이동시킨다.
positions[globalId.x] += transform(angle, (positions[globalId.x] - mousePosition)) * speed * deltaTime;
// 회전 방향도 deltaTime에 기반하여 조금씩 이동시킨다.
particle[globalId.x].angle += 0.0001 * deltaTime;
}
fn transform(angle: f32, position: vec2f) -> vec2f {
let resolution = uniforms.resolution;
// 저마다 다른 비율에서도 원이 1:1 비율을 유지하도록 하기 위해, 캔버스 비율을 고려한다.
let ratio = resolution.x / resolution.y;
let size = .25;
let x = ratio * cos(angle) * (position.x + size) - sin(angle) * (position.y + size) - size;
let y = ratio * sin(angle) * (position.x - size) + cos(angle) * (position.y - size) + size;
return vec2f(x, y);
}
이제 마우스 위치에 기반하여, 수많은 파티클이 흩날리면서도 흐릿한 원의 형태를 그리는 것을 확인할 수 있다.
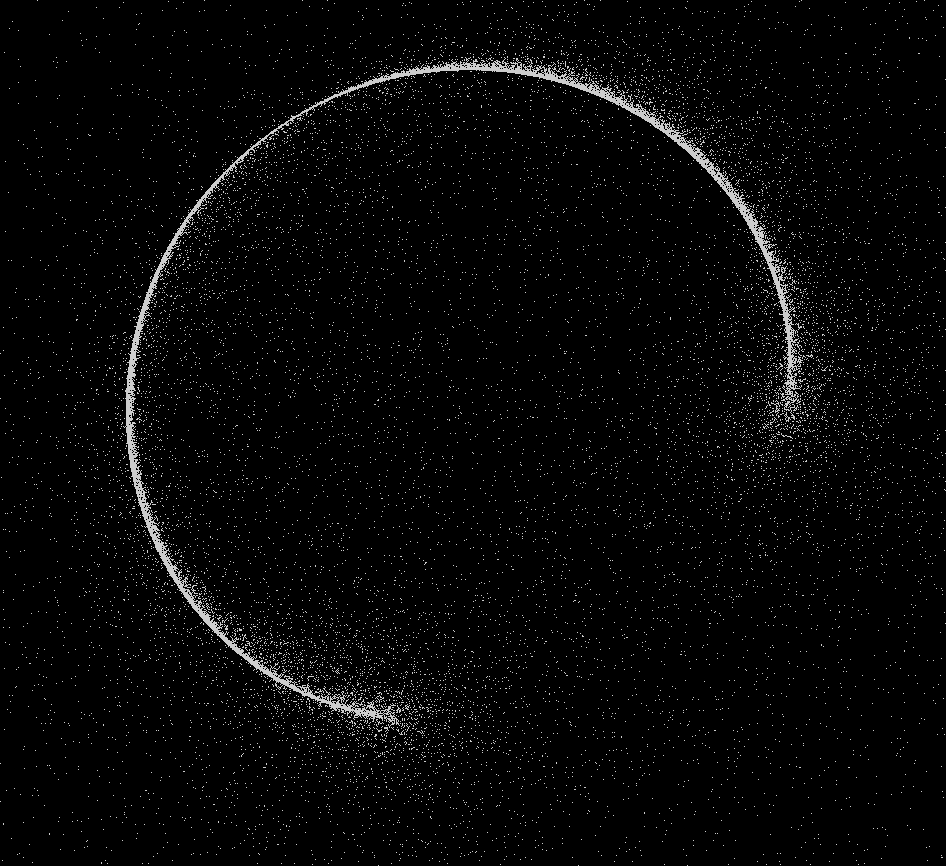
디테일 다듬기
크게 중요한 부분은 아니지만, 내 경우에는 좀 더 모래 먼지 같은 느낌을 주고 싶어 컬러를 조정해주고, 파티클 개수를 200_000개로 수정해주었다.
const POINT_COUNT = 200_000;
// ...
const renderPassDescriptor = {
colorAttachments: [
{
view: context.getCurrentTexture().createView(),
loadOp: 'clear' as const,
storeOp: 'store' as const,
clearValue: { r: 0.2, g: 0.3, b: 0.4, a: 1 }, // clear 컬러를 수정
},
],
};
// ...
프래그먼트 셰이더에서 먼지의 색상을 조절한다.
@fragment
fn fragmentMain(in: VSOutput) -> @location(0) vec4f {
return vec4f(vec3f(.8, .8, .6), 1.);
}
최종적인 구현 결과는 아래와 같다. (WebGPU가 지원되지 않는 디바이스 및 브라우저의 경우 정상적으로 로드되지 않는다.)

CPU 버전으로도 만들어보기
그래서, 이게 CPU 버전에 비해 얼마나 빠를까? 라는 궁금증을 해소하기 위해, 컴퓨트 셰이더가 아닌, JS에서 로직을 직접 처리하는 CPU 버전으로도 한번 동일한 내용을 구현해보았다. (다소 지저분한 코드에 대한 양해를 구한다. 😅)
const USE_COMPUTE_SHADER = false;
// ...
if (USE_COMPUTE_SHADER) {
// ... 기존의 컴퓨트 셰이더를 통한 구현 내용
} else {
// Use CPU version
// JS 측에서 직접 각 데이터에 접근하여 수정을 가한다.
// 로직 자체는 컴퓨트 셰이더에서 구현했던 내용과 동일하다.
const resolution = [canvas.width, canvas.height];
const _mousePosition = [
mousePosition?.x || canvas.width / 2,
canvas.height - (mousePosition?.y || canvas.height / 2),
].map((v, i) => (v * 2 - resolution[i]) / resolution[i]);
pointPositions.forEach((_, index) => {
if (index % 2 === 0) {
const position = [
pointPositions[index] - _mousePosition[0],
pointPositions[index + 1] - _mousePosition[1],
];
const angle = particleData[index * 2];
const speed = particleData[index * 2 + 1];
const transform = () => {
const ratio = resolution[0] / resolution[1];
const size = 0.125;
const x =
ratio * Math.cos(angle) * (position[0] + size) -
Math.sin(angle) * (position[1] + size) -
size;
const y =
ratio * Math.sin(angle) * (position[0] - size) +
Math.cos(angle) * (position[1] - size) +
size;
return [x, y];
};
const transformed = transform();
pointPositions[index] += transformed[0] * speed * deltaTime;
pointPositions[index + 1] += transformed[1] * speed * deltaTime;
}
}
이제 차이를 더 명확하게 파악하기 위해 파티클의 개수를 백만개로 크게 많이 늘린 뒤, 각 버전 간의 성능을 비교해보았다.
const POINT_COUNT = 100_0000;
성능 비교에 있어서는 144Hz의 재생률 모니터와 MacBook M1 Pro 16인치 32GB 2021년 모델을 기준으로 테스트했고, 따로 CPU 쓰로틀링은 적용하지 않았다.
CPU 버전
JS 측에서 데이터를 처리하는 CPU로 구현한 버전의 경우, 한 눈에 보기에도 확연한 프레임 드랍이 눈에 띄었다. CPU 사용량이 거의 100%에 가깝게 계속해서 유지되는 모습도 확인할 수 있다. JS로 직접 데이터를 변수에 저장하고, 수정하기 때문에 힙 크기도 250MB로 꽤 크게 유지되는 문제도 있다.
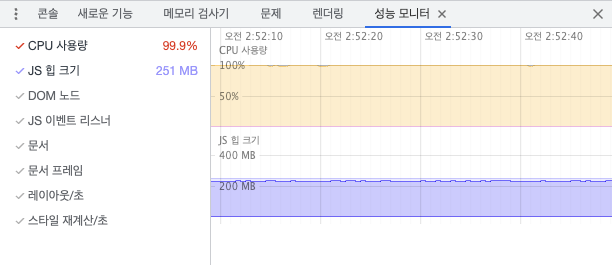
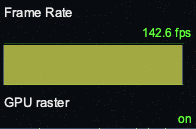
GPU 버전
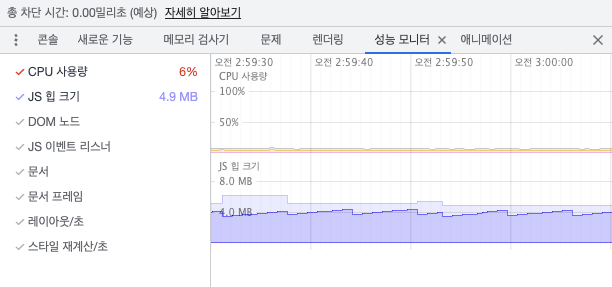
반면, 컴퓨트 셰이더를 활용하는 GPU 버전의 경우, 확실히 쾌적하게 애니메이션이 재생된다. 실제로도 144Hz의 재생률에 알맞게 144fps에 가깝게 화면을 렌더해주는 것을 볼 수 있다. 로직 처리에 CPU와 JS를 직접 사용하지 않기 때문에, CPU 사용량과 힙 크기가 현저하게 낮아진 것이 눈에 띈다.
마치며
이번 포스트에서는 WebGPU의 컴퓨트 셰이더를 사용하여 엄청 많은 개수의 파티클 연산을 처리하고, 그 결과 버퍼를 그대로 버텍스/프래그먼트 셰이더에서 사용하여 렌더링하는 방법을 다뤘다.
WebGPU는 아직까지도 실험 단계에 있는 API이긴 하지만, 컴퓨트 셰이더를 이용한 수많은 병렬 연산에 있어 엄청 강력하고, 빠른 성능을 보여주었다. 확실히 활용에 따라 무궁무진한 가능성을 보여줄 것이라 생각한다.
이번 포스트에서는 로우 레벨로 API를 이해하기 위해, WebGPU API를 있는 그대로 직접 사용해봤다. 이 포스트에서 다루는 간단한 예제를 만들기 위한 방대한 양의 코드만 살펴봐도, 이 API를 있는 그대로 사용해서 처음부터 끝까지 모두 구현하는 것은 분명 쉽지 않은 작업이다. 다만 그런만큼 구현에 있어 자유도가 높다는 것은 장점이라 볼 수 있다.
만약 나중에 유사한 형태의 구현이 요구되는 경우, WebGPU API를 직접 사용하기 보다는, BabylonJS 쪽에서 컴퓨트 셰이더를 손쉽게 사용하기 위한 API를 제공하고 있기 때문에, 추후에는 이 쪽을 사용해보는 쪽도 고려해볼 것 같긴 하다.