Data & Analytics
Amazon Athena
- S3에 저장된 데이터를 분석하기 위한 서버리스 쿼리 서비스
- 파일을 쿼리하기 위해 표준 SQL 언어를 사용 (Presto)
- CSV, JSON, ORC, Avro, Parquest 지원
- 비용: 스캔된 데이터 1TB당 5.00
- 일반적으로 Amazon Quicksight와 함께 사용하여 리포트/대쉬보드 생성
- 사례: 비즈니스 인텔리전스 / 분석 / VPC Flow Logs, ELB Logs, CloudTrail trails 등에 대한 리포팅 & 분석 & 쿼리
- 팁: 서버리스 SQL로 S3 내 데이터를 분석하고 싶다? -> Athena를 쓴다!
Athena - Performance Improvement
- 비용 절감을 위해서는 columnar data를 사용할 것 (스캔이 덜 일어남)
- Apache Parquet 또는 ORC 추천
- 높은 성능 향상
- Parquet 또는 ORC로 데이터를 변환하려면 Glue를 사용
- 더 작은 검색을 위해 데이터 압축 (bzip2, gzip, lz4, snappy, zlip, zstd...)
- 가상 컬럼을 쉽게 쿼리하기 위해 S3 내 데이터셋을 파티션
- s3://yourBucket/pathToTable
- /<PARTITION_COLUMN_NAME>=<VALUE>
- /<PARTITION_COLUMN_NAME>=<VALUE>
- ...
- /<PARTITION_COLUMN_NAME>=<VALUE>
- /<PARTITION_COLUMN_NAME>=<VALUE>
- ex.
s3://athena-examples/flight/parquet/year=1991/month=1/day=1/
- s3://yourBucket/pathToTable
- 오버헤드를 줄이기 위해서는 큰 파일(> 128MB)을 사용
Athena - Federated Query
- 관계형/비관계형/오브젝트/커스텀 데이터 소스(AWS든 온-프레미스든)에 저장된 데이터 전반에 SQL 쿼리를 실행할 수 있음
- Data Source Connector를 사용하여 AWS Lambda가 Federated Queries를 실행하도록 할 수 있음 (e.g., CloudWatch logs, DynamoDB, RDS, ...)
- 그 결과도 S3에 다시 저장

Redshift
- Redshift는 PostgreSQL 기반이지만, OLTP(online transaction processing)를 위해 사용되는 것이 아님
- OLAP임 - online analytical processing (분석 및 데이터 웨어하우싱)
- 다른 데이터 웨어하우스보다 10배의 성능 & PB(페타바이트) 단위로 확장
- Columnar storage of data (row 기반 대신) & 병렬 쿼리 엔진
- 프로비전된 인스턴스에 기반하여 비용 지불
- 쿼리 수행에 SQL 인터페이스 사용 가능
- Amazon Quicksight 또는 Tableau와 같은 BI(Business intelligence) 툴과 호환
- vs Athena: 인덱싱 덕분에 쿼리 / 조인 / 병합(aggregation)이 더 빠름
Redshift - Cluster
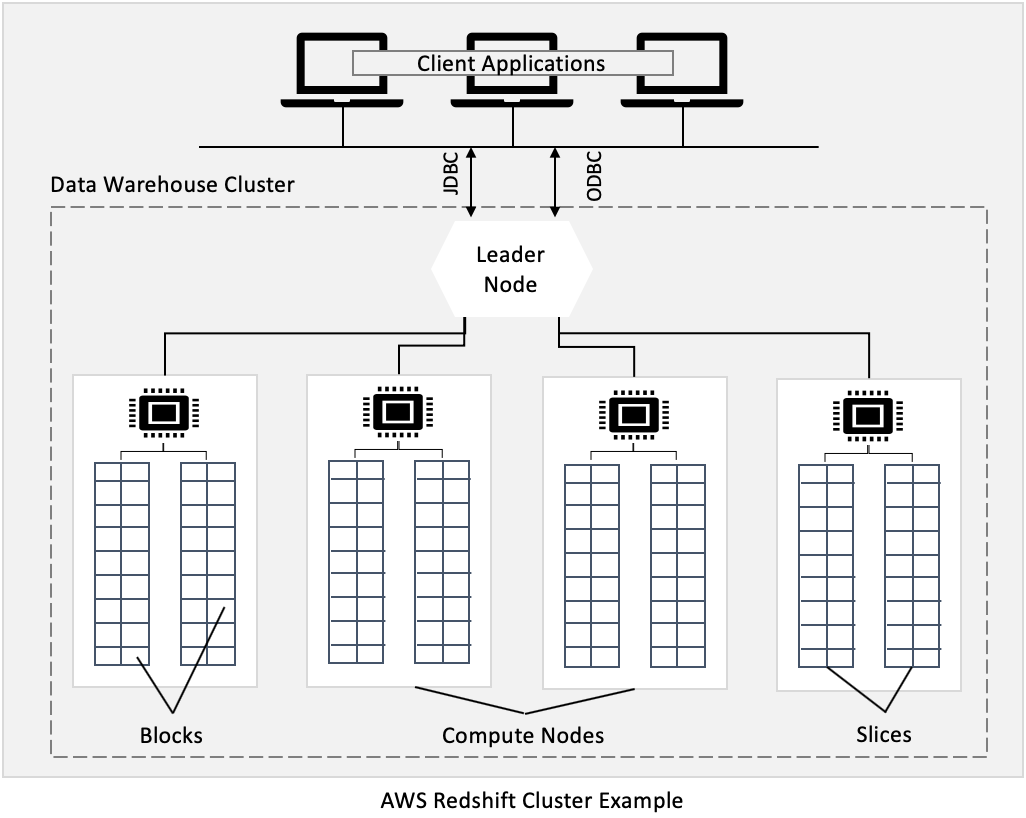
- Leader node: 쿼리 플래닝, 결과 병합 목적
- Compute node: 쿼리 수행, leader node에게 결과 전달
- 미리 노드 사이즈를 프로비전해야함
- 비용 절감을 위해 Reserved Instance 사용할 수 있음
Redshift - Snapshots & DR
- Redshift는 대부분의 클러스터에 단일 AZ이지만, 일부 클러스터에 Multi-AZ 모드를 보유함
- 스냅샷은 클러스터 하나의 point-in-time 백업이며, 내부적으로 S3에 저장됨
- 스냅샷은 incremental함 (변경이 이루어진 것만 저장됨)
- 새 클러스터로 스냅샷을 복구할 수 있음
- Automated: 매 8시간, 매 5GB, 또는 스케줄에 따라, retention을 설정
- Manual: 스냅샷을 직접 삭제하기 전까지 보존됨
- Amazon Redshift가 자동으로 클러스터의 스냅샷(automated or manual)을 다른 AWS 리전으로 복사하도록 설정할 수 있음 (disaster recovery)
Redshift - Loading data into Redshift
- insert 작업은 거대하게 처리하는 편이 훨씬 좋음
- 다음을 통해 데이터를 가져올 수 있음
- Amazon Kinesis Data Firehose - S3 copy를 통해
- S3 Bucket - 인터넷 또는 VPC를 통해서
- EC2 Instance (/w JDBC driver) ~ 배치 단위로 데이터 write를 하는게 더 좋음
Redshift - Spectrum
- 이미 S3에 있는 데이터를 따로 가져오지 않고도 쿼리
- 쿼리를 시작하기 위해 사용가능한 Redshift 클러스터를 보유해야함
- 쿼리는 수천개의 Redshift Spectrum 노드에 전달됨
Amazon OpenSearch Service
- Amazon OpenSearch = Amazon ElasticSearch의 후속 서비스 (이름이 바뀜)
- DynamoDB에서, 쿼리 작업은 반드시 primary key나 index를 포함해야 함
- OpenSearch로, 어떤 필드든 검색 가능하고, 심지어 부분 일치에 대한 검색도 가능함
- 다른 DB를 보완하는 역할로 OpenSearch를 사용하는 것이 일반적임
- 인스턴스들의 클러스터가 필요함 (서버리스가 아님)
- 기본적으로는 SQL을 지원하지 않음 (플러그인을 통해 활성화할 수는 있음)
- Kinesis Data Firehose, AWS IoT, CloudWatch Log와 호환됨
- Cognito & IAM, KMS 암호화, TLS를 통해 보안
- OpenSearch Dashboards(시각화)가 함께 제공됨
Amazon EMR
- EMR - Elastic MapReduce
- EMR은 **Hadoop 클러스터(빅데이터)**를 만드는 것을 도와 방대한 양의 데이터를 분석/처리하는 것에 도움을 줌
- 클러스터는 몇 백개의 EC2 인스턴스들로 이루어질 수 있음
- EMR은 Apache Spark, HBase, Presto, Flink와 함께 번들로 제공됨
- EMR이 모든 프로비저닝과 설정을 처리해줌
- 오토 스케일링 및 Spot instance와 호환됨
사례: 데이터 처리, 머신 러닝, 웹 인덱싱, 빅 데이터..
EMR - Node types & purchasing
- Master Node: 클러스터 관리, 좌표계(coordinate), health 관리 - 장기적으로 실행
- Core Node: task 실행 및 데이터 저장 - 장기적으로 실행
- Task Node (선택적): 오직 task 실행 목적 - 주로 Spot
- Purchasing options:
- On-demand: reliable, predictable ~ 종료되지 않음
- Reserved (최소 1년): 비용 절감 (가능한 상황이라면 EMR은 이 쪽을 자동으로 사용)
- Spot Instances: 가격이 쌈, 종료될 가능성 있음, less reliable
- long-running 클러스터 또는 transient(일시적인) 클러스터를 가질 수 있음
Amazon QuickSight
- 인터렉티브 대시보드를 만들기 위한 서버리스 머신러닝 기반의 business intelligence 서비스
- 빠름, 자동 확장 가능, 임베디드 가능, 세션 당 비용 지불
- 사례:
- 비즈니스 분석
- 시각화 구축
- ad-hoc 분석 수행
- 데이터를 통한 비즈니스 인사이트 획득
- RDS, Aurora, Athena, Redshift, S3... 등과 호환
- QuickSight로 데이터를 가져올 경우 SPICE 엔진을 통한 인-메모리 계산
- Enterprise edition: Column-Level security(CLS) 설정 가능

QuickSight - 대시보드 & 분석
- 이용자 정의(standard version), 그룹 정의(enterprise version)
- 여기서 정의된 이용자 & 그룹들은 오직 QuickSight 내에서만 존재, IAM이 아님!
- 대쉬보드?
- 공유가 가능한 읽기 전용 스냅샷
- 분석에 대한 설정이 보존됨 (필터링, 파라미터, 컨트롤, 정렬)
- 이용자나 그룹에게 분석이나 대시보드를 공유할 수 있음
- 대시보드를 공유하려면, 먼저 반드시 게시(publish)를 해야함
- 대시보드를 보는 이용자들은 그 아래 놓인 데이터도 확인할 수 있음
AWS Glue
- 관리형 ETL (extract, transform, load) 서비스
- 분석을 위해 데이터를 준비/변형하는데 유용함
- 완전한 서버리스 서비스
Glue - Data Catalog
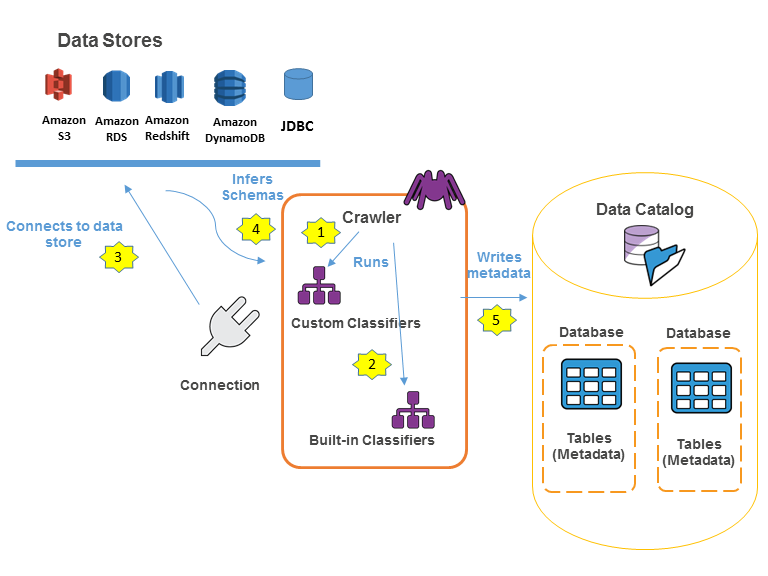
Glue - thinks to know at a high-level
- Glue Job Bookmarks: 기존 데이터의 재처리(re-processing)을 방지
- Glue Elastic Views:
- SQL을 통해 여러 데이터 스토어들 간에 데이터를 결합/복제
- 커스텀 코드 없음, Glue가 소스 데이터 내 변화를 감지함, 서버리스
- "virtual table" 활용 (materialized view)
- Glue DataBrew: pre-built transformation으로 데이터를 정리 및 정규화
- Glue Studio: Glue에서의 ETL 작업들을 생성/실행/모니터링하기 위한 GUI
- Glue Streaming ETL(built on Apache Spark Structured Streaming): Kinesis Data Streaming, Kafka, MSK(관리형 Kafka)와 호환
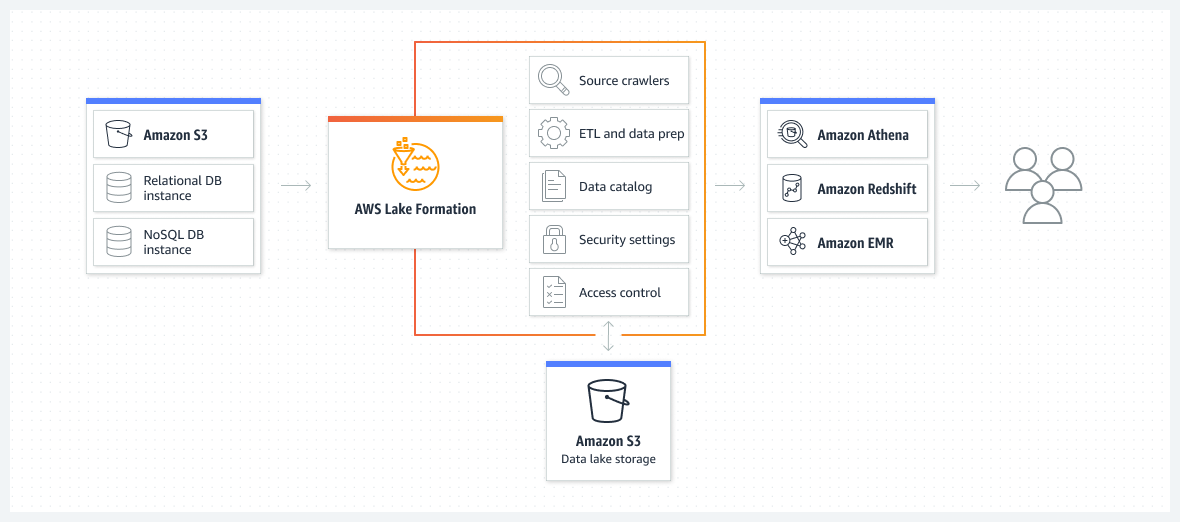
AWS Lake Formation
- Data lake = 분석 목적으로 모든 데이터들을 모아두는 중앙 위치(central place)
- 며칠 만에 data lake를 쉽게 설정할 수 있도록 해주는 완전 관리형 서비스
- Data Lake에다 데이터를 발견, 정화, 변형, 수집
- 직접 처리하기 복잡한 여러 작업들(collecting, cleansing, moving, catalog data, ...)을 자동화시켜줌, 중복 제거(ML Transform을 사용)
- data lake 내에서 구조화/비구조화 데이터를 결합
- out-of-the-box source blueprints: S3, RDS, Relational & NoSQL DB...
- 애플리케이션에 대한 Fine-grained Access Control(row/column level)
- AWS Glue를 기반으로 구축
Kinesis Data Analytics
Kinesis Data Analytics - for SQL applications
- SQL로 Kinesis Data Streams & Firehose에서 실시간 분석
- Amazon S3에서 스트리밍 데이터를 풍부하게 하기 위해 레퍼런스 데이터를 추가
- 완전 관리형, 프로비전해야하는 서버 없음
- 자동 스케일링
- 실제 사용률에 기반하여 비용 지불
- Output:
- Kinesis Data Streams: 실시간 분석 쿼리의 결과에 대한 stream을 생성
- Kinesis Data Firehose: 목적지(destination)에 분석 쿼리 결과를 전송
- 사례:
- 시계열 분석
- 실시간 대시보드
- 실시간 통계

Kinesis Data Analytics - for Apache Flink
- 스트리밍 데이터 처리 및 분석을 위해 Flink(Java, Scala or SQL)를 사용
- AWS 내에서 관리되는 클러스터에 Apach Flink 애플리케이션을 실행
- 프로비전된 컴퓨팅 리소스, 병렬 컴퓨팅, 자동 스케일링
- 애플리케이션 백업 (체크포인트와 스냅샷으로 구현)
- 어떤 Apache Flink 프로그래밍 기능이든 사용 가능
- Flink는 Firehose로부터 결과를 읽어올 수 없음 (이 경우 Kinesis Analytics for SQL을 사용해야 함)

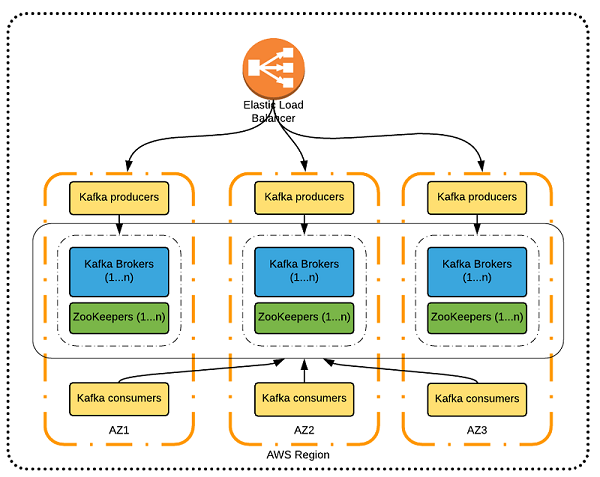
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- Amazon Kinesis의 대체제
- AWS에서의 완전 관리형 Apache Kafka
- 클러스터를 생성/수정/삭제하도록 해줌
- MSK는 Kafka broker 노드와 Zookeeper 노드를 생성 & 관리해줌
- 내 VPC 내에 MSK 클러스터를 배포, multi-AZ (최대 3개 ~ HA)
- 일반적인 Apache Kafka 장애로부터 자동 복구
- 원하는 기간만큼 EBS 볼륨에 데이터를 저장
- MSK Serverless
- capacity를 관리하지 않고도 MSK에 Apache Kafka를 실행
- MSK가 자동으로 리소스 프로비저닝 / 컴퓨팅 및 스토리지 스케일링을 처리해줌
Kinesis Data Streams vs. Amazon MSK
- Kinesis Data Streams
- 메시지 사이즈가 1MB로 제한
- 샤드로 데이터 스트리밍
- 샤드 스플리팅 & 머징
- TLS in-flight 암호화
- KMS at-rest 암호화
- Amazon MSK
- 기본 1MB, 더 높게 설정 가능 (ex. 10MB)
- Kafka Topics with Partition
- Topic에만 파티션 추가 가능
- PLAINTEXT 또는 TLS in-flight 암호화
- KMS at-rest 암호화
Amazon MSK Consumers
- Kinesis Data Analytics for Apache Flink
- AWS Glue - Apache Spark streaming으로 ETL 작업 스트리밍
- Lambda
- 직접 구축한 애플리케이션 (ex. EC2/ECS/EKS)
Big Data Ingestion Pipeline
- 완전한 서버리스로 수집 파이프라인을 구축하고 싶을 때
- 실시간으로 데이터를 수집하고 싶을 때
- 데이터 변형을 하고 싶을 때
- SQL로 변형된 데이터를 쿼리하고 싶을 때
- 쿼리를 통해 생성된 리포트를 S3에 두고 싶을 때
- 데이터를 웨어하우스로 불러와 대시보드를 만들고 싶을 때
Big Data Ingestion Pipeline discussion
- IoT Core는 IoT 디바이스로부터 데이터를 수확(harvest)할 수 있게 해줌
- Kinesis는 실시간 데이터 수집에 유용
- Firehose는 거의 실시간(1분) 내로 S3에 데이터를 전송하도록 해줌
- Lambda는 Firehose와 함께 사용하여 데이터 변형을 할 수 있게 해줌
- S3는 SQS로 notification을 트리거할 수 있음
- Lambda는 SQS를 구독할 수 있음 (S3 -> Lambda로 connecter를 둘 수 있음)
- Athena는 서버리스 SQL 서비스로, 분석 결과를 S3에 보관할 수 있음
- 리포팅 버킷(reporting bucket)은 분석된 데이터들을 포함하게 되며, 이는 AWS QuickSight, Redshift 같은 리포팅 툴과 함께 사용할 수 있음