Databases
Choosing the right batabase
- AWS에는 선택 가능한 수많은 종류의 관리형 데이터베이스가 있음
- 아키텍처에 기반하여 올바른 DB를 선택:
- 어떤 형태의 워크로드를 수행하는가? - Read-heavy / write-heavy / balanced?
- Throughput이 요구 되는가?
- 하루 동안에 스케일링 또는 변동(fluctuate)가 요구되는가?
- 데이터가 얼마나 많이, 얼마나 오래 보관되는가? 더 커질 예정인가? 평균 오브젝트 사이즈는? 액세스 처리는 어떻게 할 것인가?
- 데이터 지속성(durability)은 어떤가? 데이터의 신뢰할 수 있는 출처는 어디인가?
- 레이턴시 요구사항은 어떤가? 여러 이용자가 동시에 이용할 수 있는가?
- 데이터 모델은? 어떻게 데이터를 쿼리할 것인가? joins? structured? semi-structured?
- 강한 스키마를 갖는가? 더 유연해야 하는가? 리포팅과 검색은? RDBMS / NoSQL?
- 라이센스 비용은? Aurora 같은 클라우드 네이티브 DB로 옮길 가능성이 있나?
Database Types
- RDBMS (= SQL / OLTP): RDS, Aurora - join 작업에 유용
- NoSQL - no joins, no SQL: DynamoDB(~JSON), ElastiCache (key/value pairs), Neptune (graphs), DocumentDB (for MongoDB), Keyspaces (for Apache Cassandra)
- Object Store: S3 (큰 오브젝트의 경우) / Glacier (백업 / 아카이빙 용도)
- Data Warehouse (= SQL Analytics / BI): Redshift (OLAP), Athena, EMR
- Search: OpenSearch (JSON) - 자유 텍스트, 비정형 검색(unstructured searches)
- Graph: Amazon Neptune - 데이터 간의 관계 표시
- Ledger: Amazon Quantum Ledger Database
- Time series: Amazon Timestream
Amazon RDS - Summary
- 관리형 PostgreSQL / MySQL / Oracle / SQL Server / MariaDB / 커스텀
- 프로비전된 RDS 인스턴스 사이즈와 EBS Volume 타입 & 사이즈
- 스토리지에 대한 가용량(capacity)를 오토 스케일링
- Read Replica와 Multi AZ 지원
- IAM, Security Groups, KMS, SSL in transit을 통한 보안
- Point-in-time 복구 기능으로 자동 백업 (최대 35일까지)
- 장기 복구를 위한 수동 DB 스냅샷
- 유지보수 관리 및 예약 (downtime 포함)
- IAM 인증 및 Secret Manager와의 호환
- RDS 인스턴스에 접근 및 커스터마이징하기 위하여 RDS Custom 사용 가능 (Oracle & SQL Server)
사례: 관계형 데이터셋 저장(RDBMS / OLTP), SQL 쿼리와 트랜잭션을 수행해야 하는 경우
Amazon Aurora - Summary
- PostgreSQL / MySQL과 호환가능한 API, 스토리지와 컴퓨팅 분리
- Storage: 데이터가 3개의 AZ에 걸쳐 6개의 replica에 저장됨 - high available, self-healing, auto-scaling
- Compute: multi-AZ를 통한 DB 인스턴스 클러스터, Read Replica에 대한 오토 스케일링
- Cluster: writer와 reader DB 인스턴스에 대한 커스텀 엔드포인트
- RDS와 동일한 보안 / 모니터링 / 유지보수 기능
- Aurora의 백업 및 복원 옵션
- Aurora Serverless - 예측 불가능한 / 간헐적(intermittent) 워크로드, capacity planning 필요없음
- Aurora Multi-Master - 지속적인 write 장애 조치를 위함 (high write availability)
- Aurora Global: 각 리전마다 최대 16개의 DB 읽기 인스턴스, 1초 이하로 걸리는 스토리지 복제
- Aurora Machine Learning: SageMaker와 Comprehend를 통해 Aurora에서 ML을 수행
- Aurora Database Cloning: 기존에 존재하는 클러스터를 통해 새 크러스터를 만듬, 스냅샷 복구보다 빠름
사례: RDS와 동일하지만, 유지보수에 대한 신경이 덜하고 / 더 유연하며 / 더 성능 좋고 / 더 많은 기능을 보유
Amazon ElastiCache - Summary
- 관리형 Redis / Memcached (RDS와 유사하지만, 캐시를 위한 것임)
- 인-메모리 데이터 스토어, ms 미만의 레이턴시
- 반드시 EC2 인스턴스 타입을 프로비전
- 클러스터링(Redis)과, Multi AZ, Read Replica (sharding)을 지원
- IAM, Security Groups, KMS, Redis Auth를 통한 보안
- 백업 / 스냅샷 / Point-in-time 복구 기능
- 유지보수 관리 및 예약
- 활용하기 위해서는 애플리케이션 코드에 대한 변경이 필요함
사례: Key/Value 스토어, 빈번한 read / 적은 write, DB 쿼리 결과 캐싱, 웹사이트 세션 데이터 저장, SQL은 쓸 수 없음
Amazon DynamoDB - Summary
- AWS 독점의 관리형 서버리스 NoSQL 데이터베이스, ms 단위 레이턴시
- capacity mode:
- provisioned capacity (오토 스케일링 옵션 있음)
- on-demand capacity
- key/value 스토어로서 ElastiCache 대체 가능 (ex. TTL 기능을 사용하여 세션 데이터 저장)
- 기본적으로 High Available, Multi AZ이며, 읽기/쓰기 작업이 분리(decoupled)되어 있고, 트랜잭션 기능 있음
- 읽기 작업 캐싱을 위한 DAX cluster - ms 단위의 읽기 레이턴시
- IAM을 통해 보안, 인증, 권한 부여 처리
- 이벤트 처리: DynamoDB Stream은 AWS Lambda 또는 Kinesis Data Stream과 호환됨
- Global Table 기능: active-active 셋업
- 최대 35일까지 PITR(point-in-time recovery)를 통한 자동 백업, 또는 on-demand 백업
- Read Capacity Unit(RCU) 없이도 PITR window 내에서 S3로 내보내기 가능, WCU(Write Capacity Unit) 없이도 S3로부터 가져오기 가능
- 빠르게 발전하는 스키마에 유용함
사례: 서버리스 애플리케이션 개발 (데이터가 작을 때, < 100KB), 분산된 서버리스 캐시
Amazon S3 - Summary
- 오브젝트에 대한 key/value 스토어
- 오브젝트가 큰 경우에 유용, 여러 개의 작은 오브젝트들에는 썩 좋지 않음
- 서버리스이고, 무한하게 확장하며, 최대 오브젝트 사이즈는 5TB, 버저닝 기능 있음
- Tiers: S3 Standard, S3 Infrequent Access, S3 Intelligent, S3 Glacier + lifecycle policy
- Features: Versioning, Encryption, Replication, MFA-Delete, Access Logs, ...
- Security: IAM, Bucket Policies, ACL, Access Points, Object Lambda, CORS, Object/Vault Lock
- Encryption: SSE-S3, SSE-KMS, SSE-C, client-side, TLS in transit, default encryption
- Batch operations: S3 Batch를 이용해 오브젝트들에 대한 배치 작업, S3 Inventory를 사용해 파일 리스팅
- Performance: Multi-part upload, S3 Transfer Acceleration, S3 Select
- Automation: S3 Event Notifications (SNS, SQS, Lambda, EventBridge)
사례: 정적 파일, 거대한 파일들에 대한 key-value 스토어, 웹사이트 호스팅
DocumentDB
- Aurora가 PostgreSQL / MySQL의 AWS 구현 버전이었다면, DocumentDB는 MongoDB를 위한 AWS 구현 버전 (이것도 NoSQL)
- MongoDB는 JSON 데이터를 저장, 쿼리, 인덱싱하기 위해 사용됨
- Aurora의 배포 컨셉(deployment concept)과 유사함
- 완전 관리형이며, 3개의 AZ에 복제함으로써 highly available
- DocumentDB 스토리지는 10GB씩 자동으로 확장됨, 최대 64TB
- 초당 수백만(million) 건의 요청이 발생하는 워크로드에 맞게 자동으로 확장됨
Amazon Neptune
- 완전 관리형 그래프(graph) 데이터베이스
- 소셜 네트워크와 같은 graph dataset에 사용됨
- user는 friend들을 가짐
- post는 comments들을 가짐
- comment는 user로부터 like를 가짐
- user는 post를 share하거나 like를 함
- 3개의 AZ에 걸쳐있고, 최대 15개의 read replica를 통해 highly available함
- 서로 강하게 연결되어 있는 데이터셋들을 사용하는 애플리케이션을 빌드 및 실행
- 이러한 복잡하고 어려운 쿼리들에 최적화됨
- 최대 10억(billion)개의 관계(relation)을 저장하며, 그래프 쿼리를 ms단위로 수행할 수 있음
- multi AZ에 replication을 두어 Highly available함
- 지식 그래프(knowledge graphs ~ ex. Wikepedia), 사기 감지(fraud detaction), 추천 엔진, 소셜 네트워킹에 유용함
Amazon Keyspaces (for Apache Cassandra)
- Apache Cassandra - 오픈소스 NoSQL 분산형 데이터베이스
- 관리형 Apache Cassandra 호환 데이터베이스 서비스
- 서버리스, scalable, high available, fully managed by AWS
- 애플리케이션 트래픽에 기반하여 테이블 개수를 자동으로 scale up/down
- 테이블은 multi AZ로 3번 복제됨
- CQL(Cassandra Query Language) 사용
- 어떤 스케일링이든 한자릿수 ms 레이턴시, 매초 1000개의 요청
- Capacity: on-demand mode 또는 provision mode(오토 스케일링 가능)
- 암호화, 백업, 최대 35일까지 Point-In-Time Recovery 가능
사례: IoT 디바이스 정보 저장, 시계열(time-series) 데이터
Amazon QLDB
-
QLDB - Quantum Ledger Database
-
ledger - 금융 거래(financial transactions)를 기록하는 장부
-
완전 관리형, 서버리스, HA, Replication across 3 AZ
-
시간이 지나도 애플리케이션 데이터에 이루어진 모든 변화의 히스토리를 리뷰해야하는 경우에 사용
-
Immutable 시스템: 어떤 항목도 삭제되거나 수정될 수 없음, 암호화 검증 가능(cryptographically verifiable)
-
일반적인 ledger 블록체인 프레임워크보다 2-3배 더 좋은 성능, SQL로 데이터 조작
-
Amazon Managed Blockchain과의 차이: 탈중앙화(decentralization) 컴포넌트가 아님, 금융 규체 규칙(financial regulation rules)에 따름
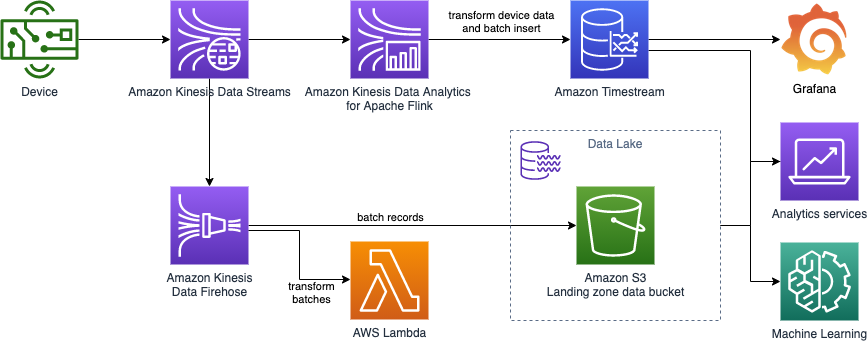
Amazon Timestream
- 시계열(time series) 데이터베이스
- 완전 관리형, 빠름, scalable, 서버리스
- 자동으로 capacity를 scale up/down
- 매일 1조(trillion)개의 이벤트를 저장 및 분석
- 1000배 빠름 & 관계형 DB보다 1/10의 비용
- 예약 쿼리(Scheduled queries), 다중 측정 레코드(multi-measure records), SQL 호환성
- Data storage tiering: 최근의 데이터는 메모리에 저장되고, 과거 데이터는 비용 효율적인 스토리지에 저장됨
- 빌트인 시계열 분석 함수 (실시간으로 데이터에 대한 패턴을 파악하는데 도움을 줌)
- in-transit 암호화, at-rest 암호화
사례: IoT 앱, 운영 앱, 실시간 분석, ...